Közismert kritika, ellenérv a Linux rendszerek használata ellen az, hogy nincs (ingyen) professzionális, vagy legalábbis jó képességű magyarul beszélő OCR-szoftver a rendszerre. Miről is van szó egész pontosan? Az OCR az optikai karakterfelismerés angol rövidítése, szinte minden szkennerhez mellékelnek (változó minőségben és változó magyar nyelvi támogatással) ilyen alkalmazást. Röviden: a szkennerbe beletesszük a teleírt, leginkább gépelt, nyomtatott lapot, az OCR-alkalmazás pedig elolvassa és digitalizálja a lapon látható szöveget egy állományba, ami ezután jellemzően egy szövegszerkesztőbe behívható fájlt eredményez.

A módszer segítségével nagyságrendekkel gyorsul a papíralapú dokumentumok elektronikussá alakítása, legyen szó akár egy régi szerződésről, vagy egy nyomtatott könyv lapjaiból e-book készítéséről.
OCR terén hazánk nagyhatalom, elég, ha a legendás Recognita programra gondolunk, ami az – azóta már felvásárolt – egykori Scansoft cég terméke. Átlagos Windows-felhasználók körében nem titok, hogy abban az esetben, ha a megvásárolt szkennerhez nem járt a gyári telepítőlemezen normális OCR-megoldás, a problémát a Recognita telepítésével szokás megoldani.
Házi OCR-barkács
Mi a helyzet Linuxon? A nyílt forráskódú platformra nincs Recognita, és más neves termékek sem igazán jelentek meg a szabad operációs rendszerre. Nyílt forrású megoldások persze vannak, ilyen például a GOCR vagy a CUNEIFORM, amelyek ingyenesen telepíthetők a disztribúciók tárolóiból, de a minőségük elmarad a várttól, és a magyar nyelv speciális karaktereivel is nehezen barátkoznak meg. Mit tehetünk? A problémára az openSUSE/Little Susie internetes fórumának lakói készítettek egy érdekes megoldást, ahol meglévő, jó minőségű programok apróbb módosításával és „összeházasításával” állt össze egy egészen jól használható, házi OCR-programcsomag.
Az alap a TESSERACT volt, amely egy OCR-motor, amit eredetileg a HP fejlesztett ki, de a minősége nem érte el az általuk elvárt szintet. Ugyanis nem egyszerűen csak egy működő programot szerettek volna létrehozni, hanem egy piacvezető színvonalú megoldást. A szoftver ezt a reményt nem teljesen váltotta be, de még így is messze meghaladta az átlagot, az elvégzett tesztek szerint a kor három legjobb minőségű terméke között szerepelt.
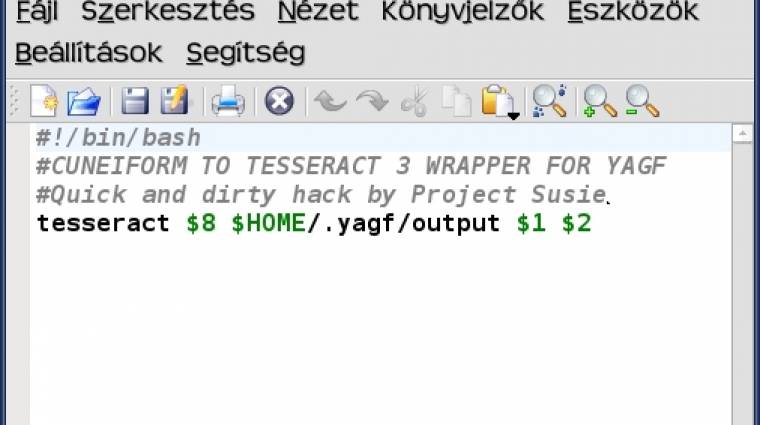
A TESSERACT fejlesztése aztán átkerült a nyílt forrású közösséghez, jelenleg Google-projektként működik, és rengeteg nyelv speciális karakterkészletét és írásmódját támogatja; ezek a bővítések egyfajta betanított formátumban tölthetők le, és telepíthetők a megfelelő mappába. A GUI: a CUNEIFORM OCR-hez egy orosz programozócsoport készített egy szép, jól használható, független és ingyenes grafikus felületet, ez a YAGF (neve betűszó, a Yet Another Graphical Frontend for Cuneiform rövidítéséből fakad), ami a TESSERACT használatához is átalakítható, illetve újabb változatai most már eleve számolnak ezzel a felhasználással is. Ami összeköti őket: egy néhány soros kis „wrapper script”, tehát egyszerű bash parancsfájl, ami a YAGF által a CUNEIFORM számára kiadott utasításokat „értelmesen eltéríti”, átértelmezi és továbbítja a TESSERACT program számára, majd annak kimenetéről a YAGF ugyanúgy begyűjti az eredményt, mintha eredeti partnerével dolgozna.

Kezdjünk hozzá
Little Susie- és openSUSE-felhasználók a következő címen tölthetik le egy böngésző segítségével a telepítendő csomagokat (más disztribúció esetén a csomagkezelő, illetve a komponensek fejlesztőinek honlapján található csomagok lehetnek segítségünkre). A letöltött állományokban megtalálható a TESSERACT és a YAGF RPM-csomagja, és cuneiform álnévre hallgató script is. Töltsük le és telepítsük a két RPM-et. (Függőségeik a csomagkezelő segítségével teljesíthetők.) A cuneiform fájlt – root joggal – a /usr/bin könyvtárban helyezzük el, és tegyük futtathatóvá. (Amennyiben rendszerünkre már telepítettük előzőleg a cuneiform programot, azt előtte távolítsuk el, vagy a /usr/bin/cuneiform bináris állományból készítsünk egy átnevezett, mentett változatot, például cuneiform.bak néven)
Használatba vétel
Amennyiben minden jól ment, és az esetleges függőségeket is helyesen feloldottuk, akkor a YAGF ikonja máris látható lesz a (K)menü -> Grafika -> Szkennelés menüpont alatt (KDE3 felületen). Kattintsunk rá (ha nem indul, adjuk ki a yagf parancsot konzolon, így megláthatjuk, milyen hiba okozhatja a sikertelen telepítést). Amennyiben betöltődött a YAGF, máris magyar nyelven dolgozhatunk egy kétablakos felületen, ahol a bal oldalra hívhatjuk be az előzőekben már mentett szkennelt képfájlokat (vagy vezérelhetjük innen is a lapolvasást). Az OCR gombra kattintva – a dokumentum terjedelmétől függően rövidebb-hosszabb várakozási idő után – a jobb oldali ablakban feltűnik majd az elolvasott, legépelt szöveg, amit természetesen még mentenünk kell szöveges állományként.
Tippek útravalóul
A YAGF menüjében nem árt magyarra állítani az olvasandó szöveg nyelvét, ugyanis ez paraméterezi a TESSERACT OCR-motort. Ha a TESSERACT fejlesztői oldaláról letöltjük egyéb nyelvek támogatását is, akkor a wrapper és a YAGF apróbb reszelgetése árán ezek is használatba vehetők. A Little Susie tárhelyén lévő TESSERACT-csomag a magyar nyelv támogatását beépítve tartalmazza. A többi disztribúció tárolóiból általában csak az angol érhető el, ezekben az esetekben az egyéb, használni kívánt nyelvek támogatását külön kell letöltenünk.

A fent megadott, Little Susie tárhelyén lévő YAGF-verzió (többé-kevésbé, körülbelül 96 százalékban) teljesen magyar nyelvű. Azok számára, akik eltérő disztribúciót használnak, az elérhető csomagok általában nem biztosítják a magyar nyelvű felület lehetőségét. A magyar nyelvi fájl egyébként külön is letölthető a Little Susie tárhelyéről. A yagf_hu.qm állományt ebben az esetekben a /usr/share/yagf/translations könyvtárban kell elhelyezni. Fontos azonban, hogy a verziók különbsége esetén a magyarításban hibák jelentkezhetnek.
A wrapper script jelenleg csak a minimálisan szükséges funkciókat látja el, igény esetén bátran lehet próbálkozni – a TESSERACT és a YAGF paramétereinek, lehetőségeinek ismeretében – a funkciók bővítésével, módosításával. Például a scriptbe „beletoldott” egy-két sor segítségével láthatóvá tehetjük a YAGF által kiadott egyéb parancsokat, és azokat megfelelő formálás után a TESSERACT bemenetére küldhetjük.
A megfelelő beolvasás fontossága nem elhanyagolható szempont a hibátlan szöveghez. Az OCR-programok például általában kevésbé szeretik a Serif (talpas) betűtípusokat, a Sans Serif-jellegű betűformákkal elérhető eredmények szinte mindig jobbak. Az „olvasás” során nem mellékes tényező a betűk mérete sem. A beolvasott állományban 8 pixeles betűméret esetén a szöveg nagy részét zajnak fogja értékelni a program. A minimális – még értékelhető eredménnyel feldolgozható – betűméret 10 pixel körül van. Általánosságban elmondható, hogy a kiváló eredmény legalább körülbelül 20–27 pixel méretű beolvasott karaktereket kíván. Mivel egy nálunk használatos, átlagos papírlap leginkább A/4 formátumú, és még nagy, jól olvasható nyomtatott betűk esetén is legalább 40 sort tartalmaz, így a sorközöket is bekalkulálva nem árt legalább 300 dpi, vagy annál nagyobb, körülbelül 600 dpi szkennerfelbontást használni. (A túl nagy, például 1200 vagy 2400 dpi felbontásnak az esetek túlnyomó részében már nincs értelme, csak feleslegesen megnöveli a feldolgozási időt. Kétszeres dpi-érték körülbelül négyszeres feldolgozásiidő-növekedést jelent.)
Türelmes beállítás és jó levilágítás mellett a fenti szoftver-összeállítás teljesen ingyen szinte csodákra képes, akár egy mobiltelefonnal lefényképezett könyvlapot is képes részben olvasható, gépelt szöveggé varázsolni. Természetesen az ingyenes, közösségi alapokon készített alkalmazástól nem szabad a méregdrága, professzionális programok összetett szolgáltatásait elvárnunk, mivel nem egy kategóriában versenyeznek, de házi vagy kisebb irodai, szűkebb költségvetésű intézményi felhasználásra kisebb kompromisszumok és megfelelő odafigyelés árán ingyen is juthatunk jó minőségű programokhoz.
A helyesírás-ellenőrző bekapcsolása jelentős mértékben képes javítani a nyers olvasási minőségen, nem árt a csomagkezelőben a spell-hu és a spell-en kifejezésekre keresni, amelyek szinte minden magyar és angol helyesírás-ellenőrzőt listáznak. (A YAGF egyébként alapesetben az aspell-t használja)
Bátor, haladó linuxosok megpróbálkozhatnak a TESSERACT és a YAGF forrásnyelvi csomagból történő elkészítésével, telepítésével is Előbbi esetén a Google Code-os új fejlesztői honlapon, illetve a régi SourceForge oldalán érdemes keresgélni. A YAGF esetén pedig annak a hivatalos oldalán, illetve a Freshmeaten találhatunk segédletet.
A fenti összeállítással kapcsolatos, fejlesztés közben felmerült kérdések és válaszok, problémák és megoldásaik elolvashatók az openSUSE, azon belül a Little Susie fórumában.
