
Sok cég látja a jövőt a mesterséges intelligenciában, annak viszont érdeklődőnek kell lennie, ha meg akarja tanulni, hogyan működik a világ.
Az elmúlt években ez egy visszatérő kérdés az AI fejlesztésében. A Google DeepMind divíziója megmutatta, hogyan dolgoznak ezen a témakörön, illetve, hogyan lesz okosabb az AI.
A Google AI ügynöke mostanában az Atari köztudottan nehéz Montezuma's Revenge játékával játszik. Nem úgy azonban, mint a StarCraftnál vagy egyéb játékoknál a botok, amelyek a játék összes adatával rendelkeznek.
Az AI az emberhez hasonlóan játszott és játszik, vagyis kísérletezik: feldolgozza a képernyőn látottakat, nyomogatja a gombokat, és megnézni, hogy mi működik és mi nem.
Februárban ezt a kísérletet már megpróbálta a DeepMind, akkor azonban nem ért el pontot az AI. Mostanra profi lett.
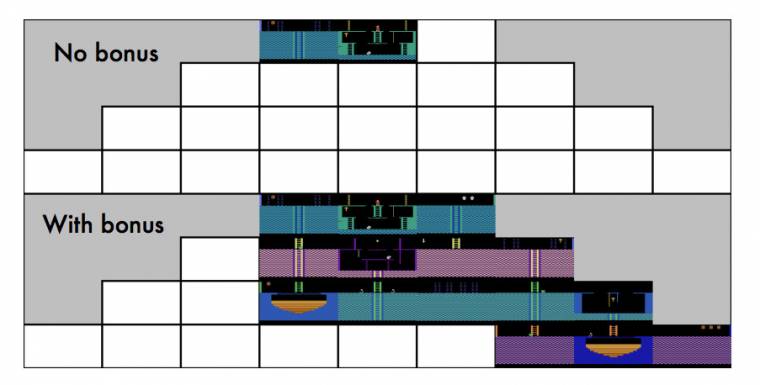
Miért? Azért, mert az AI-t belsőleg jutalmazták. Ahogyan az emberi agy kémiailag jutalmazza önmagát, addig az AI egy jutalomrendszert kapott, ami ehhez hasonló. A digitális jutalmazást összekötötték a mesterséges intelligencia felfedezőrendszerével, amely így érdekelt lett a környezete felderítésében. Nem maradt el az eredmény sem: bónusz nélkül az AI 2, bónusszal 15 szobát látott.
A való világban persze nehezebb a feladat, elvégre más a környezet, a veszélyek, és nincs több élete a rendszernek.
