Egyre gyakrabban hallunk valamilyen áttörésről a mesterséges intelligencia kapcsán. Azonban az algoritmusok finomítása nem könnyű munka, az AI számára nem egyszerű megtanítani, hogy felismerje az adatokban az egyes mintákat, vagy megjósolja azokat.
Mindehhez óriási mennyiségű, már előre felcímkézett információra van szükség. Ezek alapján lehet tanítani és tesztelni az intelligens rendszereket.
A Google két új módon segíti ebben a kutatókat. Az Open Images a Google, a Carnegie Mellon és a Cornell együttműködésében kínál képeket, 9 milliót.
Ezek mindegyikét gépek címkézték fel, hogy aztán a feliratokat emberek pontosítsák. Ennyi képpel már lehet oktatni egy neurális hálózatot a nulláról is.
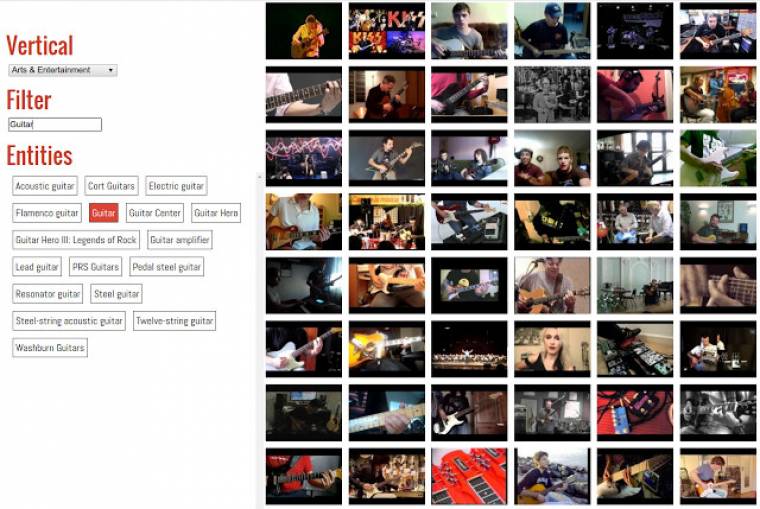
A munkát segíti még a YouTube8-M is, ami 8 millió videót (több mint 500 000 órányi felvétel) tartalmaz. Az adatbázis a videós analízist segíti. A Google emellett az állóképeket is mentette és címkézte, amelyek szintén letölthetőek.
A Google segítségének hála mindegy, hogy valaki a következő Prisma appot, robotautós AI-t vagy mást szeretne fejleszteni, az adatbázisok már rendelkezésre állnak a munkához.
