
Azt gondolhatnánk, hogy a nyári hónapok még úgyis nyugodtabb munkanapokat okoznak, hogy a nagy tech cégek egyébként gőzerővel készülnek az iskolakezdésre és az ünnepi szezonre időzített termékek bevezetésére. Kevés a felhajtás és új termék, ami épp megérkezik a forró hónapokban, tömegesen csak a szeptemberi felpörgésnél lesz érdekes a célközönség számára.
Valamiért az idei év más; az Intel épp a legsötétebb korszakának küszöbén áll (pontosabb fél lábbal már belépett erre az ösvényre), a legutóbbi pénzügyi jelentés szerint borús jövőkép rajzolódik ki a cégvezetés számára. Mi is szót ejtettünk pár idei botrányról, de naivan azt gondoltuk, hogy hasonlóra nem kell számítani az év hátralevő részében.
A legfrissebb híradások szerint most az Nvidia került bajba, és a következő generációs Blackwell AI-gyorsítóban talált tervezési hiba csak a kezdet.
Sajátosan értelmezik a szerzői jogokat
A mesterséges intelligencia alapú technológiákkal szembeni aggodalmakra eddig nem igazán érkeztek megnyugtató válaszok, ami már csak azért sem meglepő, mert hihetetlen rövid idő alatt képes tovább fejlődni, éven belül érhetők el nagyobb mérföldkövek; ezek befogadása pedig nem egyszerű.
Az Nvidiáról tudhatjuk, hogy a piaci dominanciájuk egyik alapja a felpörgetett fejlesztési ütem, az AI-gyorsítók és ökoszisztémák értékesítése nem várhat évekig, most kell ütni a vasat, amíg meleg. Ez a túlfűtött állapot érződik a tőzsdéken is, nagyon úgy fest, hogy a felfújt lufi kezd elvékonyodni, és ebből még óriási, recesszióba mutató pofára esés lehet.
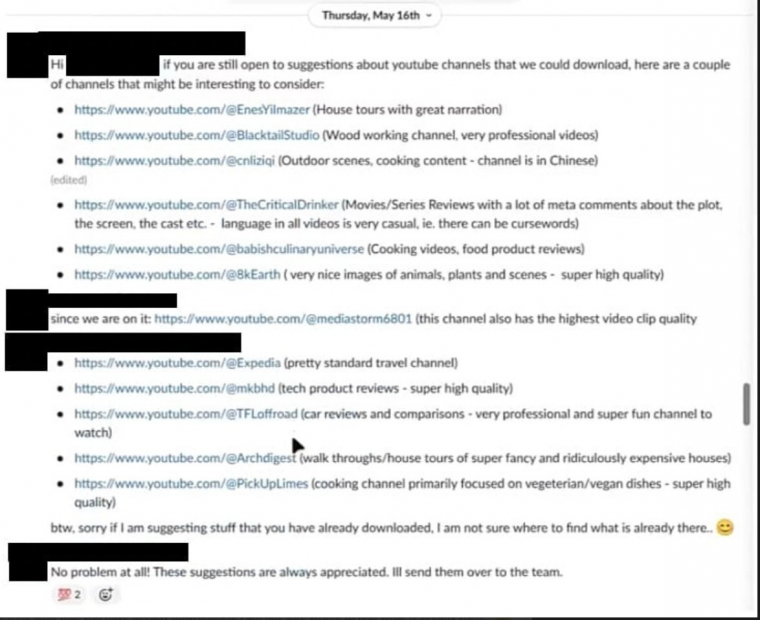
A sürgetés egy természetes velejárója a mesterséges intelligenciára vonatkozó jövőképnek, és ennek erejét most kiszivárgott Slack-üzeneteken, leveleken és dokumentumokon látni. Az Nvidia belsős AI csapatának párbeszédeiből nemcsak az olvasható ki, hogy adattípust és mennyiséget nem kímélve igyekeznek feltanítani modelleket különböző projektekhez, hanem felsővezetői szintű engedélyt kaptak YouTube, Netflix videók, és egyéb, videótárak és könyvtársak használatára.
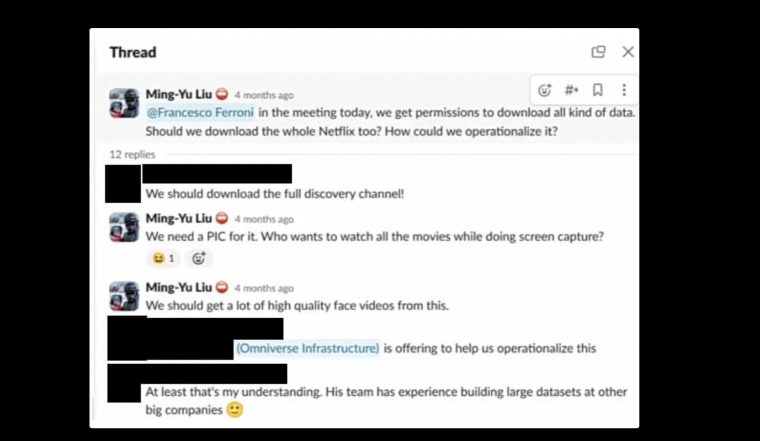
A projektben résztvevőkben felmerültek aggályok a tartalmak engedély nélküli felhasználása kapcsán, a szerzői jogok betartása mellett etikai kérdésekkel fordultak közvetlen feletteseik felé, de ezekre általános megerősítés érkezett, a "zöld lámpa" a legfelsőbb szinteken villant fel.
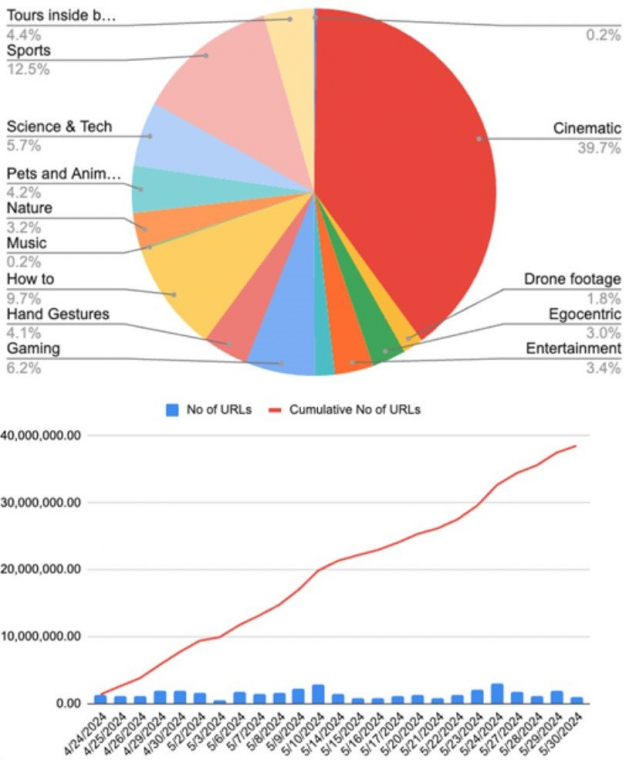
38,5 millió videó URL az első félévben
A párbeszéd, amiben a Netflix teljes letöltésére vonatkozó kérdés szerepel, egészen morbid, és a mára eléggé megfáradt "letöltöm az egész internetet" vicceskedéssel hozható egy szintre; csak itt most nem tréfálnak.
Belső kimutatásból tisztán látszik, hogy hány linket vontak be a projektbe, és milyen arányban vannak az egyes tematikák, mint pl. zene, természetfilm, gaming, mozifilm. Utóbbi kapcsán külön forrásokat vontak be a projektbe, amiben mozielőzeteseket használtak fel a modellek feltanítására. Bár felfedezhető némi bizarr lazaság az üzenetváltások között, a kirótt feladatok és a vezetői beszámolók alapján az Nvidiánál bizony komoly háttérmunka zajlott vagy még most is zajlik.
Hogy mindez probléma-e? Nézőpont kérdése, az Nvidia szerint az eljárásukkal nincs semmi gond, és minden szerzői joggal kapcsolatos szabályt és etikai szellemiséget betartanak. Különben is, szerintük a szellemi jogok is csak különleges kifejezésekre érvényesíthetők, tényekre, ötletekre, információkra nem. Meglehetősen egyedi értelmezéssel állunk szemben, és konkrétan abból indulnak ki, hogy a videók megtekintésével megszerzett információkhoz, adatokhoz és az ebből kialakuló tanulási folyamathoz nekünk, természetes személyeknek is jogunk van. Következésképp egy AI betanítására is alkalmazható.
A YouTube oldaláról természetesen nem ennyire megértőek, és konkrét válaszukban a felhasználási feltételek megsértését említik. Sőt, korábbi példákkal erősítették ezen véleményüket, és tartanak ki amellett, hogy a platformon található videók nem használhatók fel AI-modellek tanítására.
Tudományos vagy kereskedelmi cél?
Ingoványos terület, és vélhetően az Nvidia is abba kapaszkodik, hogy ők bizony csak tudományos céllal használják fel ezt a több tízmilliónyi videóanyagot; ez pedig engedélyezett. A gond csak az, hogy a kiszivárgott üzenet szerint a felsővezetés természetesen a jövőben kereskedelmi céllal értékesítendő modellekre érti a "zöld lámpa" adását, és maga Jensen Huang nevezi "Nagyszerű előrelépésnek." az AI csapat vezetőjétől érkező aktuális helyzetjelentés a feltanítás állapotáról. A már készre tanított, illetve kiépített rendszer konkrét ajánlatként állítható össze az érdeklődő partnerek számára.
Nem ez lesz az utolsó eset, amikor egy, a technológiában érdekelt óriásvállalat üzleti érdekeinek megfelelően használ fel harmadik féltől származó anyagokat, adatokat. A mesterséges intelligencia gyors ütemű fejlődése ráadásul láthatóan kiskapukat hagy, illetve teret a sajátos értelmezésekre; erre a botrányra sem fogunk emlékezni fél év múlva, illetve egyelőre azt sem tudni, ki szállhat szembe az AI-óriásokkal. A Google? A Netflix? Miért is tenné? A tartalomgyártók? Sok sikert az Nvidia jogi csapatával szemben.
Persze, vegyük ezt komolyabban, de sajnos teljesen érthető, ha jogi szempontból sokan még nem érzik komfortosnak a mesterséges intelligencia kapcsán megindított csatákat. És az is szinte borítékolható, hogy ilyen ütemű fejlődés mellett a szerzői jogok fogalmát is kénytelenek leszünk újraértékelni, hiszen gyakorlatilag már most is követhetetlen, ami a szöveg-, zene-, és képalkotás terén történik, és még csak az elején vagyunk mindennek.
