
Talán még emlékezhetnek rá a mesterséges intelligenciával kapcsolatos híreket vadászó olvasóink, miszerint a Google 2014-ben megvásárolta a Deepmind nevű céget, amely pontosan ezzel, a gépi gondolkodás és logika fejlesztésével foglalkozott. A megavállalat berkeiben természetesen továbbra is ez maradt az irány, és nemsokára meg is alkották az AlphaGo nevű programot, ami legyőzte a játék "emberi" világbajnokát, a dél-koreai Lee Sedolt.
Oké, mondhatná bárki, hogy ez még nem a Skynet, de azt érdemes tudni, hogy mondjuk egy sakkprogramhoz képest a go sokkal inkább "emberi" gondolkodást igényel, az jóval több szabadságfokot kínáló ősi kínai játékban ugyanis sokkal több szerepe van a kreatív és intuitív megközelítésnek. Szóval míg egy sakkprogramot nagyjából úgy programoznak előre, hogy betáplálják az összes addigi játszma összes lépését, a go esetében csomó egyéb okosságra is szükség van. No, és pont ez az, amiben mostanra még nagyobbat lépett a Google, a mesterséges intelligenciájának új változata, az AlphaGo Zero ugyanis elődjével ellentétben magától tanult meg játszani.
"Talnulni, tanulni, tanulni!" (Lenin) "Oké, oké, oké" (Google)
Az AlphaGo-t ugyanis még úgy tanították, hogy egyszerűen beletáplálták százezer go-játszma adatait, és innentől hagyták gondolkodni. Ehhez képest az AlphaGo Zero semmi mást nem kapott induláskor, csupán a go szabályait: innentől "magára hagyták", tehát tanuljon, kísérletezzen, és saját maga ellen játszva építse fel ugyanezt a tudásbázist.
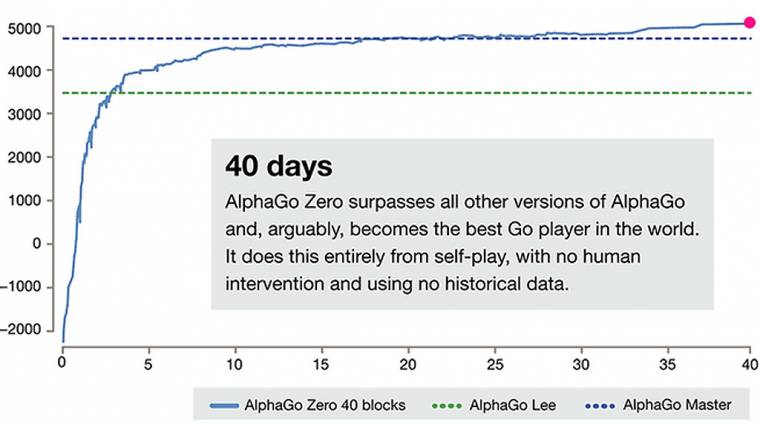
A Zero elég durván startolt: már három nap alatt olyan szintre jutott, hogy száz meccsből százszor megverte elődjét (ami ugyebár már eleve jobb volt, mint a legjobb emberi játékos). 40 napos fejlesztés (pontosabban önfejlesztés) után pedig a szakértők úgy vélik, 3000 év teljes go-tudását sajátította el önmagára utalva a program. A mostani sikerben pont ez a lényeg a Deepmind szerint: az AlphaGo Zero úgy tanult, hogy semmilyen emberi korlát nem akadályozta, saját logikája szerint jutott idáig.
A go után persze van tovább, a Google sem csak azért szórakozik a robotaggyal, hogy megszeppent táblajátékosokat hagyjon maga után. A vállalat leginkább orvosi kutatásokban szeretné bevetni a rendszert, amelyet máris ráállítottak komplex fehérjék szerkezetének elemzésére, hogy olyan betegségeket is gyógyítani lehessen, mint a Parkinson- vagy Alzheimer-kór.
Egyébként azon se csodálkoznánk, ha a mindenható mesterséges intelligencia nemsokára tényleg elférne egy mobilon: míg az első AlphaGo egy 48 processzoros szupergépen futott, a Zero már "csak" egy olyan hardvert igényel, amelyben két speciális felépítésű MI-processzor dolgozik.
